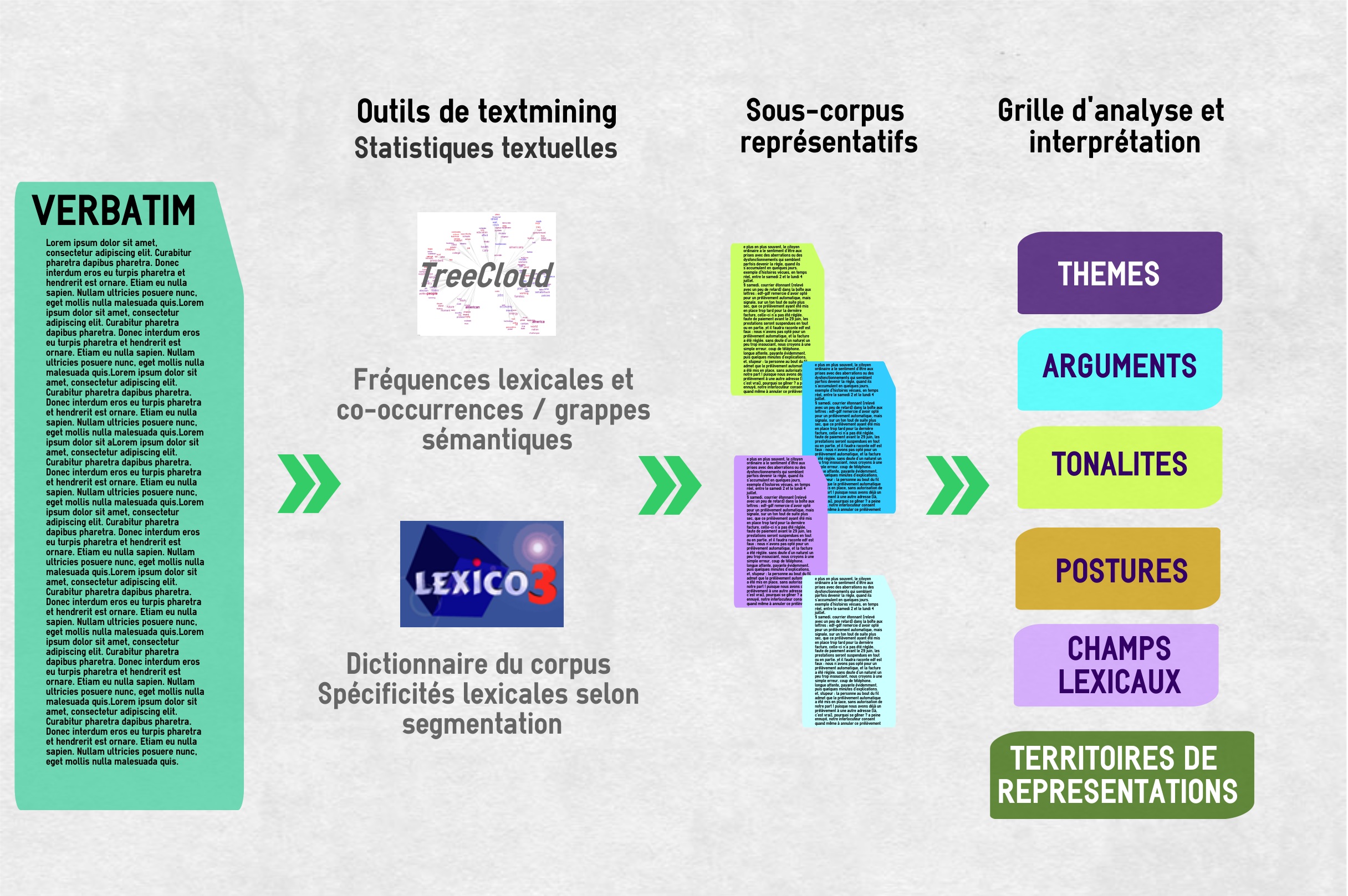
La visualisation des mots les plus représentatifs extraits de milliers de données, nous permet d'identifier des sous-échantillons pertinents à analyser en profondeur via notre grille d'analyse sémiologique.
Nuage arboré (fréquences et co-occurrences lexicales)
Capture Ecran du logiciel TreeCloud sur la base d’un corpus de commentaires Deezer / Outil conçu par Philippe Gambette (Laboratoire d’informatique LIGM Marne la Vallée UMR 8049) à partir du concept de visualisation proposé par Jean Véronis
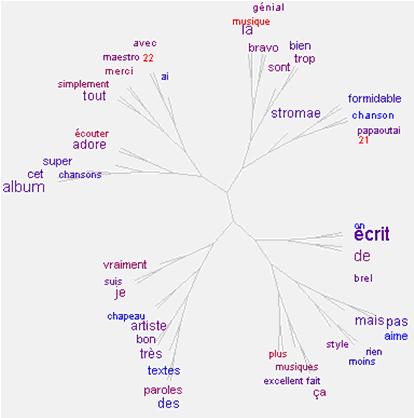
Les statistiques textuelles permettent également d’identifier les spécificités lexicales d’un corpus par rapport à un autre via un calcul de probabilité (coefficient de spécificité ou non spécificité).
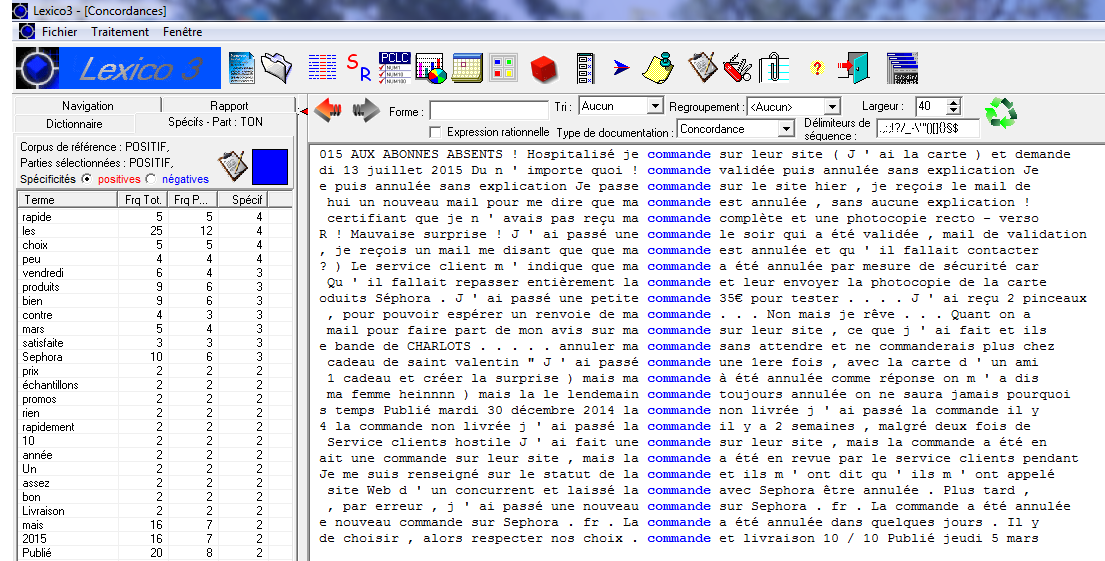
Capture Ecran d'une spécificité lexicale illustrée sur la base d’un corpus d'avis consommateurs. Visualisation avec Lexico 3, logiciel conçu pour le traitement lexicométrique, développé par le laboratoire CLA2T SYLED de l’Université de la Sorbonne Nouvelle
PCW-Etudes participe au projet de recherche Imagiweb. L'objectif de ce projet de Textmining est d'analyser le cycle de vie des images / représentations qui circulent sur le Web. En savoir plus ICI
